A new website, and a Blog!
2022-04-24
Do you know that itch when something just isn't right and you feel like it needs to change? Now, I doubt many people have this feeling regarding websites - but if you own one, you may know what I'm talking about!
I have had a website for quite some time now. See for yourself:
> git log --reverse | head -n5
commit 5dc1562a203c642b30c67e8b1a796fc31a3817a3
Author: Janrupf <[email protected]>
Date: Sun Dec 13 22:10:04 2020 +0100
Initial commit
Well, maybe not for that long. Though that's nearly 1 and half a year! While the old site might not seem that bad at first glance, it has become quite a burden to maintain.
You see, when I initially set this thing up I wanted to create a super modern experience. Something like a portfolio, a really fancy one! I jumped right into the tech stack, set up Webpack, Typescript and Vue. Cool, now we have a production ready single-page application with a few thousand dependencies.
Actually, I wanted to count them... but turns out, when you are using Yarn 2, you can't easily do that. So well, here goes npm again:
> npm i -D
~~ snip ~~
added 788 packages, and audited 789 packages in 24s
99 packages are looking for funding
run `npm fund` for details
5 high severity vulnerabilities
To address all issues (including breaking changes), run:
npm audit fix --force
Run `npm audit` for details.
Soooo, just 788 packages for only a start page, additionally 5 possible high severity security vulnerabilities for free.
You couldn't ask for more! I feel like this project is built on a really stable base.
Measuring the size of node_modules doesn't convey a better feeling either: 186MB for nothing! To emphasize this once
again, this is from a point in time, where the site only had a nearly empty start page.
But let's continue, since I used and developed the website for over a year using this base, it surely must have been fast to build? Right? Right?!
> time yarn build
~~ snip, lots of webpack output ~~
yarn build 15.39s user 0.44s system 180% cpu 8.754 total
Mhhhm... ok, so it takes a bit over 15 seconds to build an empty start page. And not only that, it includes 5 possible vulnerabilities, dozens of deprecations I have no control over and a disk usage of 186MB.
Alright, I may be dramatizing a bit here. The 186MB are development utilities and most of this won't end up in the final site, neither will the 5 vulnerabilities. In fact, the final website has a size of around 308K, which is perfectly acceptable.
Let's fast-forward to the last change I made to the old website and see how things are looking there. Running the same
measurements as above (I'll spare you the command output), we end up with 486 packages, 0 vulnerabilities and a
node_modules directory with a size of 176MB.
Ok what... so apparently, my website shrunk over a year of development? Then again, it's only the development tools, not the project itself. Though, now it refuses to build, because I apparently didn't properly lock my Webpack dependency version - now it's incompatible. Great! Let me quickly fix that with some vim magic...
After all, we end up with a new build time of 29 seconds. At least all the deprecation warnings and vulnerabilities are gone, however, as they never made it into the website anyway, this is not really important. The website has grown to a respectable size of 14MB.
12.9MB of this is a single video, the demonstration video of Snowland to be exact. Javascript takes 168K, which is... quite unsettling. The size of HTML in exchange is quite low, with a whopping 4K bytes!
Well, time to analyze what we are doing:
> du -shc dist/**/*.js
8.0K dist/115.bundle.js
8.0K dist/149.bundle.js
8.0K dist/599.bundle.js
8.0K dist/655.bundle.js
8.0K dist/728.bundle.js
128K dist/bundle.js
168K total
> du -shc dist/**/*.html
4.0K dist/index.html
4.0K total
du conveniently is able to summarize entire directories with a bit of bash (cough zsh) pattern matching.
Interestingly we also only have one HTML file, explaining the small size. Something seems quite fishy nevertheless, all
of our Javascript bundles are exactly 8K and our HTML file is 4K.
Taking a look at the HTML file indeed tells us that there is no way it contains 4096 bytes of information:
<!-- prettified for the sake of readability !-->
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>janrupf.net</title>
<script defer="defer" src="bundle.js"></script>
</head>
<body>
<div id="app"></div>
</body>
</html>
You know what? I think du is lying! Luckily we have another tool available, wc, which can also count bytes.
Running it on the index file...
> wc -c dist/index.html
179 dist/index.html
Aha! 179 seems much, much more reasonable! So for some reason du is not telling us the truth. I really want to know
why, so lets... actually, lets not dig into that, not now at least. We still want to find out, why our site is using
much more Javascript than HTML. Exploring why tools disagree on file sizes is a question for another post.
See, our index.html contains nearly no content at all, in fact, just loading it without any context yields a white
page and a Javascript error. I for a fact though know that I have way more than just that index, so where did all that
fancy remaining code go? And while we are at it, where even is my CSS?
It surely must have gone somewhere, since the site works just fine once we load the index.html within its directory.
And the only thing I can see in its source code is that suspicious reference to bundle.js, which thanks to du we
know is quite large (compared to the other files at least).
Let's take a look at bundle.js... or maybe not. Everything is one line, minified and squished together. Not readable
at all, and it doesn't tell us anything about where our content went. I'm not ready to give up though! Sometimes you
need to look at a problem from a different perspective - reversing the approach!
I think I just know the solution, we search our files for content. Take page about other projects for example:
<template>
<div class="page-container">
<div class="flex-2"></div>
<div class="flex-2">
<h1 class="center-text page-title">Side and fun projects</h1>
</div>
<div class="flex-3 load-animation">
<ProjectList :projects="projects" />
</div>
<div class="flex-2"></div>
</div>
</template>
<script lang="ts">
import ProjectList from "./ProjectList.vue";
import SnowflakePNG from "../../themes/neutral/snowflake.png";
import EEPBridgeLogo from "../../themes/neutral/eep-bridge-icon.png";
export default {
name: "OtherProjects",
components: {ProjectList},
setup() {
const projects = [
{
title: "Xmas countdown",
imgSource: SnowflakePNG,
description: "Just what this world needed!",
routerLink: "/xmas-counter"
},
{
title: "EEP Bridge",
imgSource: EEPBridgeLogo,
description: "Companion application for EEP for advanced control",
homepage: "https://github.com/Janrupf/eep_bridge_host"
}
];
return { projects };
}
};
</script>
This is a perfect candidate! It only includes a single string "Side and fun projects" in its HTML which is easy to search.
We could fiddle around with grep, Linux' standard search utility, but I much more enjoy using
ripgrep. Ripgrep calls its own executable rg, which we can use to search
the dist directory:
> rg -l "Side and fun projects" dist
dist/728.bundle.js
Since we already know everything is on one line, and we anyway only care about the file, we tell ripgrep to only print
the filenames using -l.
So our string ended up in 782.bundle.js! Which means our HTML is... in a Javascript file.
I don't think HTML belongs there, unless... unless it is inserted at runtime, which would explain why just loading our
index.html with all surrounding files missing doesn't give as anything at all.
Now it all makes sense! We have so many Javascript files, because everything actually ended up being packaged in them,
even though it was CSS, HTML or whatever in the beginning. Our index.html is just a gateway to dynamically insert
all content when you, the user, visit the site. Of course this moves all the size from static self-contained text files
to Javascript files, thus creating a huge set of them.
There is yet another implication: Javascript is a programming language, which means we can, and in fact, need to execute it in order to access whatever it has in store. So now instead of your Browser receiving the content it wants to have, it instead gets a cookbook which it needs to evaluate and run through.
And we are spending 29 seconds just create this cookbook! After all, Vue, and in extension single-page applications, may be really cool for highly interactive and dynamic websites. The people who decide to use such framework when building a site are usually, including me, aware what it means and that the result is going to require a lot of Javascript.
However, requirements change! My idea went from building a portfolio with interactive projects to creating a blog and project site, which mostly consists of static, text heavy content and external links. Spending 29 seconds to build it and requiring every user's browser to run a bunch of Javascript just for that is not worth it.
VuePress could have been a solution which would have allowed me to keep using Vue while having a static set of files in the end. But my primary intention of using Vue was for interactive components, which are simply not required anymore. I'm fine with having a bunch of static text files which offer no interactivity at all.
I still could embed Vue anywhere if required, but the idea of going from a few hundred dependencies to 0 was just too good to ignore. So here we are, you are in fact reading this without requiring much, if any, Javascript at all!
Let's pretend we still need to decide how to achieve this. And let's set a few goals:
- Keep Javascript at a minimum
- Spend time on content rather than assembling the page
- Have a simple build process without much configuration
- Don't limit possibilities on what could be done, just in case
Now, what we are looking for is a static-site generator. But there are quite a few of them, like reeeaaalllly many. A few we can already rule out, NuxtJS, NextJS, VuePress, Gatsby... they all are based on Javascript, and while that technically doesn't impact the resulting website (the static-page generator is only needed to build the site once content has changed), my experience with NodeJS and generally Javascript tells me that they are going to be somewhat slow.
Yes, I know, I know, Javascript doesn't have to be bad and for many it's a really great programming language. But I want something really fast, which only gives me a tool to convert a bunch of files into static pages and doesn't force me to use any framework. So maybe I'll use one of these for another project, another site, someday - but as we are not out of options yet, let's continue the search.
Next up is Jekyll, kind of associated with GitHub. It claims to be blog-aware, focus on content and not frameworks, and after all just be a minimalistic tool. No strings attached. Moreover, it's used for GitHub pages, proving it has been successfully used at least a few million times. There is just one thing which bugs me... it's written in Ruby! Yep, here I go again, shaming programming languages. Ruby is also an awesome language, no question, but it comes with its own set of dependencies, package management and slowness.
Hugo sounds more promising. No, it's not a gnome you put into your garden! Hugo is a static-site generator written in Go, which means it compiles to machine code and thus should be fast. It doesn't require you to use a specific framework, nor is it slow. It comes with quite a powerful templating language and generally feels like a well tested choice. So let's use Hugo...
Except, maybe, maybe not! Hugo is boring, and while it perfectly fits our requirements, I wanted to see if I could get something even cooler, something written in Rust. You see, I love experimental and fresh software. So if we can find a static-site generator written in Rust, which fulfills our requirements, I'm happy. If not, I'll use Hugo.
Massive spoiler alert: This page has not been generated by Hugo, at least not as of writing this! Let me introduce you to Zola. A single static binary, with batteries included, but no junk that I don't need. It can serve my site for development with precious live reload, is more than fast (thanks Rust!) and generally has just the right features.
Perfect, done! We have a static-site generator, now we only need to write an article, publish it and... ok hold up, not so fast. Even Zola doesn't generate a site out of thin air, it needs some input. And keep in mind, we are replacing my entire website, not just the future blog part! So, just having installed Zola, what can we do with it?
> zola
zola 0.15.3
Vincent Prouillet <[email protected]>
A fast static site generator with everything built-in
USAGE:
zola [OPTIONS] <SUBCOMMAND>
FLAGS:
-h, --help Prints help information
-V, --version Prints version information
OPTIONS:
-c, --config <config> Path to a config file other than config.toml in the root of project
-r, --root <root> Directory to use as root of project [default: .]
SUBCOMMANDS:
build Deletes the output directory if there is one and builds the site
check Try building the project without rendering it. Checks links
help Prints this message or the help of the given subcommand(s)
init Create a new Zola project
serve Serve the site. Rebuild and reload on change automatically
Oh heck, if only all programs had such a useful cli. Of the few commands available, init sounds very promising.
Why don't we just invoke it and see what happens:
> zola init
Failed to create the project
Error: The current directory is not an empty folder (hidden files are ignored).
Oh ok, well, that makes sense. I ran Zola in one of the project roots, luckily it didn't clutter it but just complained about the directory not being empty.
> mkdir new-site
> cd new-site
> zola init
Welcome to Zola!
Please answer a few questions to get started quickly.
Any choices made can be changed by modifying the `config.toml` file later.
> What is the URL of your site? (https://example.com): https://janrupf.net
> Do you want to enable Sass compilation? [Y/n]: Y
> Do you want to enable syntax highlighting? [y/N]: Y
> Do you want to build a search index of the content? [y/N]: Y
Done! Your site was created in /projects/private/new-site
Get started by moving into the directory and using the built-in server: `zola serve`
Visit https://www.getzola.org for the full documentation.
This time it just runs and asks a few questions. Sass, syntax highlighting, search index... yep, count me in, I'll take
all of them! The last bit of text also tells us to run zola serve in order to use its built-in webserver. The part
about moving into the directory is a bit misleading though, we were in it already before running zola. I guess we could
have also used zola init new-site and it would have created the directory automatically. Anyway, lets take a look at
what we have now:
> tree
.
├── config.toml
├── content
├── sass
├── static
├── templates
└── themes
5 directories, 1 file
5 empty directories and a single configuration file. That's what I call minimalistic! No HTML, no CSS, no Javascript in sight, just a bare-bones structure.
For the sake of it, a sneak peek at the config.toml:
# The URL the site will be built for
base_url = "https://janrupf.net"
# Whether to automatically compile all Sass files in the sass directory
compile_sass = true
# Whether to build a search index to be used later on by a JavaScript library
build_search_index = true
[markdown]
# Whether to do syntax highlighting
# Theme can be customised by setting the `highlight_theme` variable to a theme supported by Zola
highlight_code = true
[extra]
# Put all your custom variables here
Even the configuration for the entire website is composed of 4 variables in a single file. Efficiency! Looking at text
files in a terminal is all fun and games, but we need this to work in a browser! Zola already suggested using the
serve subcommand, so here we go:
> zola serve
Building site...
Checking all internal links with anchors.
> Successfully checked 0 internal link(s) with anchors.
-> Creating 0 pages (0 orphan) and 0 sections
Done in 9ms.
Listening for changes in /projects/private/new-site{config.toml, content, sass, static, templates}
Press Ctrl+C to stop
Web server is available at http://127.0.0.1:1025
Alright, 9... 9 milliseconds! Sure, the project is empty, but even building an empty Javascript project takes ages
compared to this. The question is, will it blend work?
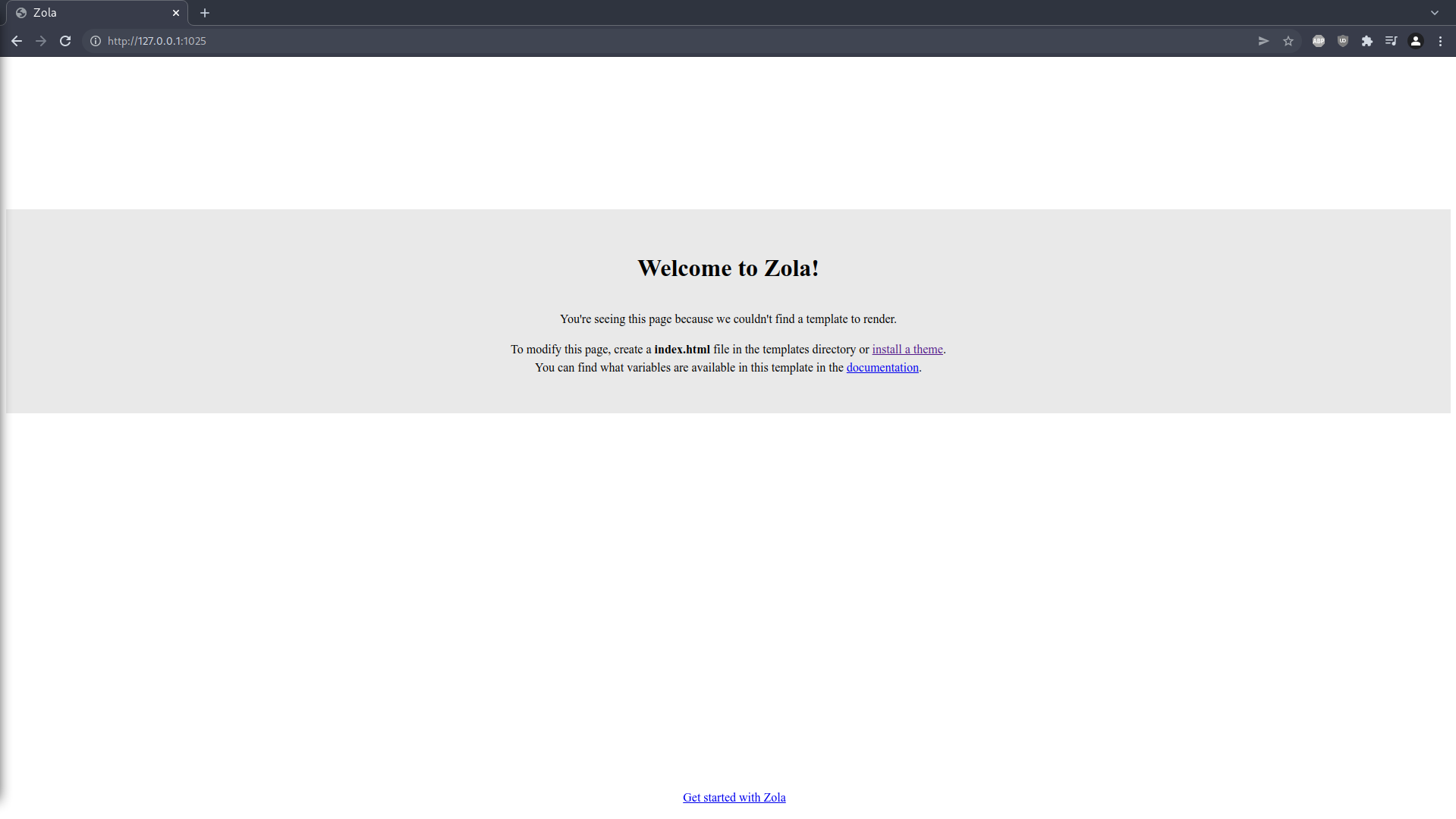
Sure enough. Interestingly Zola doesn't populate the project with some generic "getting started" page, but instead just falls back to serving a built-in page when it can't find the required files in your project.
Let's really quickly create an index.html in templates as the page suggests to us:
<!DOCTYPE html>
<html lang="en">
<head>
<title>Test 123</title>
</head>
<body>
<h1>Hello, World!</h1>
</body>
</html>
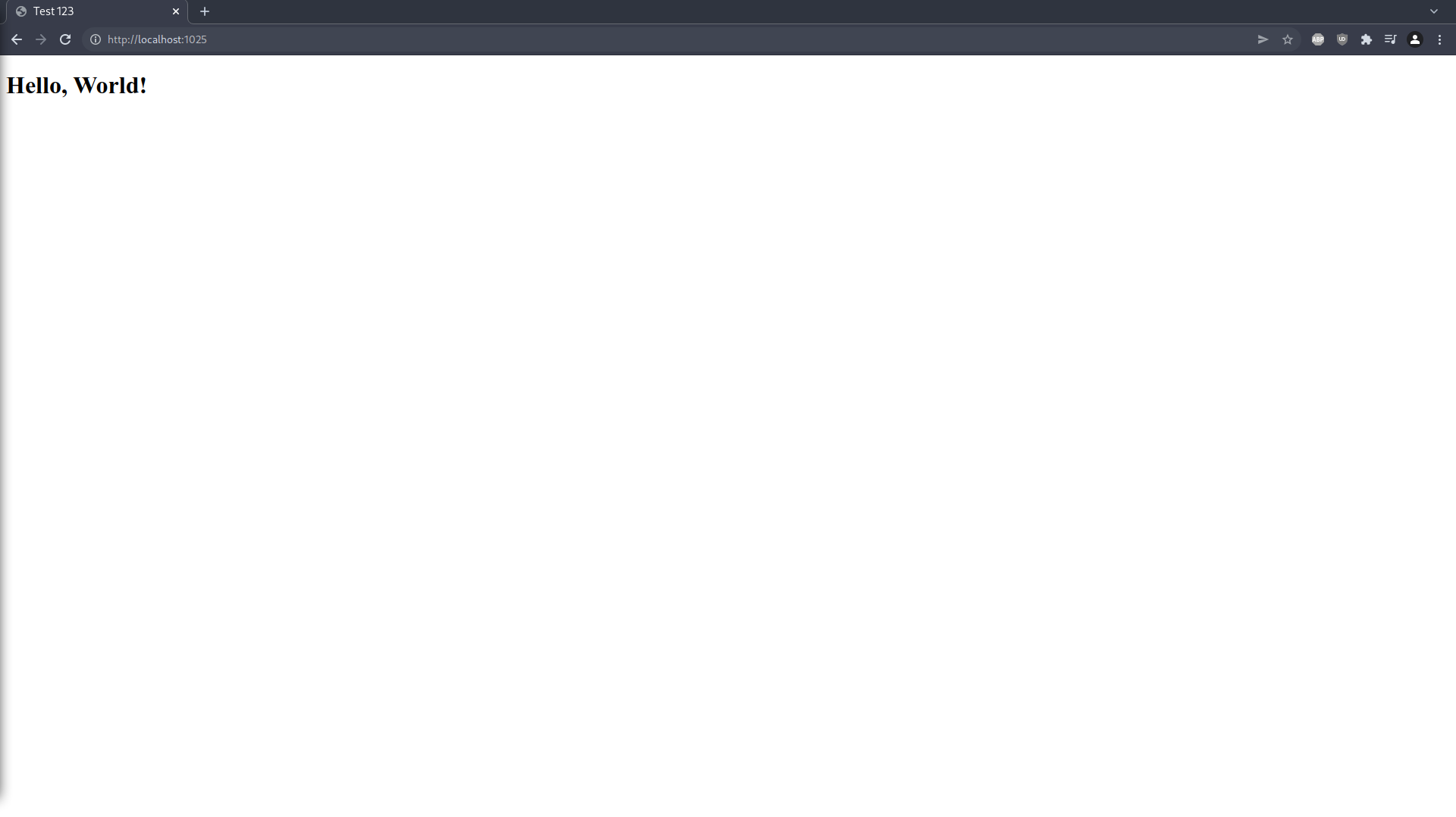
Didn't even need to reload the browser, it updated just right away! This really looks like a glorified webserver with live reload - but trust me, Zola is much, much more. But at the same time it's not too much! There is an amazing template system to explore, Markdown to HTML conversion and Sass compilation.
It took me around 8 hours to set up everything required for my new website, including the skeleton for blog posts, styling and some auxiliary stuff. Zola makes all of that really easy - it doesn't interfere with the process, requires no interaction once running and works transparently, no magic involved. Of course that means, that you for example have to write your stylesheets yourself, make up some HTML and templates, prototype a design.
Zola also supports themes, to make it even easier! However, I opted for not using one and instead went bare-bones, creating everything from scratch for a completely controlled experience. And that's the beauty of simplicity, Zola does one thing, and it does that very well! It didn't force me to use a specific framework, to import anything or have any huge dependencies. No more Javascript bundles, and it builds in 230 milliseconds (after adding quite some stuff)!
By no means is Zola free of bugs, or handles everything for me. But I got other tools to edit the content, minify the output and deploy the website.
Exploring Zola and setting all of that up is left as an exercise to the reader. The making of this website will probably not be much of a topic in the future anymore, as I certainly rather work on programs than webpages. But I think this makes a good introduction to this blog!
Not so fast!
Non-technical part ahead! It has been quite a journey up to this point. As of writing this, I haven't even finished school, but who got time for that anyways.
Creating and maintaining a blog has been a plan of mine for quite some time, and while tools such as Zola make this part easy on the technical side, there is a lot more to taking the time and finding inspiration. The writing style and page layout are heavily, heavily inspired by Amos (and his bear), go check his content out at fasterthanli.me. Nope, I don't like to copy things around and use the work of other people, but he has set a very high standard with a near to perfection style and presentation. I enjoy the content he posts, and by that his work certainly contributed a large part to the creation of this project.
Now, of course there are also quite a few people who encouraged me to set this up. Those who told me they would love to read this blog or just constantly kept asking where it is. Those who got me start projects and then pushed me through them. Payback time, here you go! So thanks, thanks to everyone.
Most of the posts are going to be quite technical ones, tearing software to pieces and putting it back together - but here and there you may find something very personal. And if you know me personally, you may even find yourself.